Mobile App That Speaks with DeepMind WaveNet Google Cloud Text To Speech ML API and Flutter
Published at Jul 29, 2018
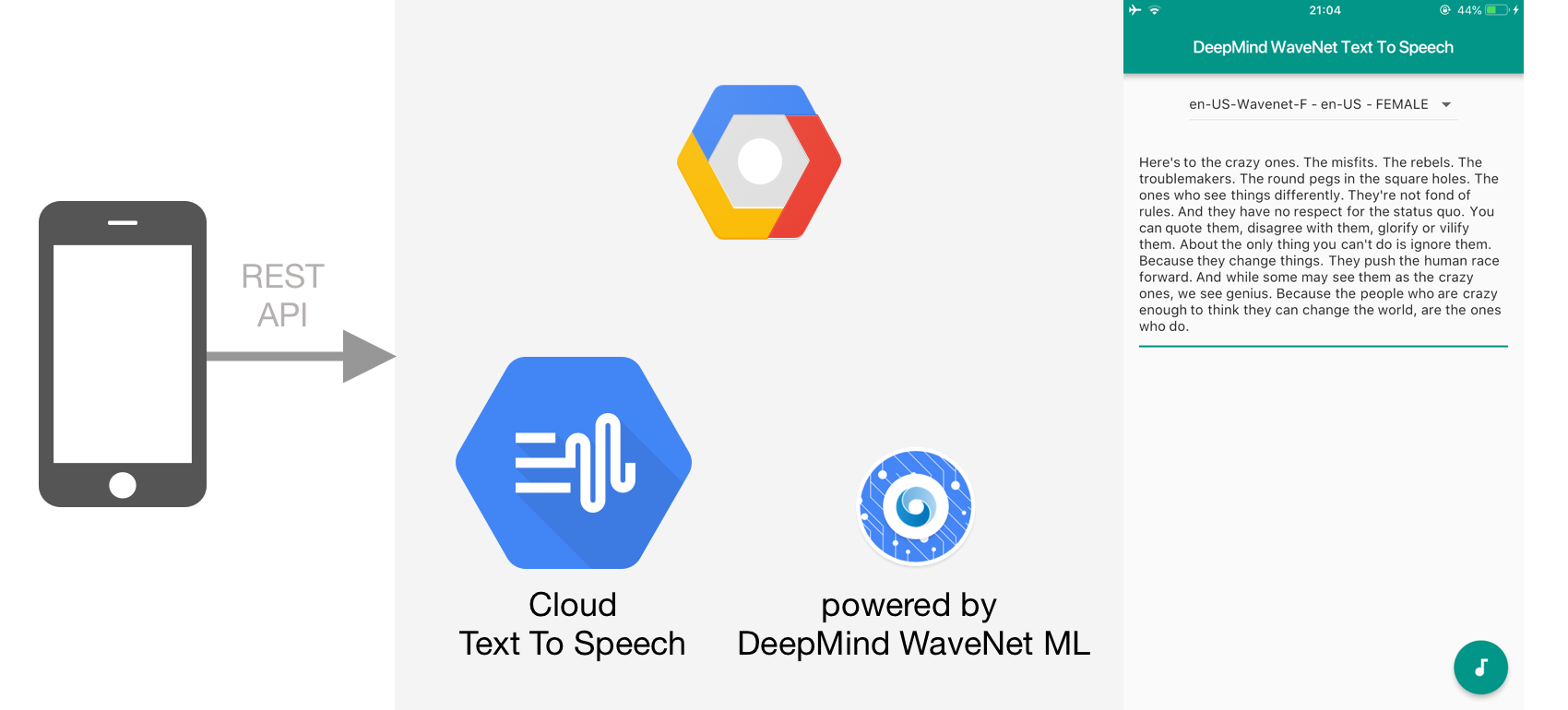
Text to Speech synthesis is the process of text transformation into human speech audio using computer. Many Operating System had built the feature for text to speech since 1990s. The advancement in Machine Learning and Artificial Intelligence in recent years results in many new advance voice synthesis technologies such as WaveNet Deep Learning Neural Network from DeepMind. According to Google:
DeepMind has made groundbreaking research in machine learning models to generate speech that mimics human voices and sounds more natural, reducing the gap with human performance by over 50%. Cloud Text-to-Speech offers exclusive access to multiple WaveNet voices and will continue to add more over time.
Google has provided Cloud Text to Speech API as a GCP service for developers to use in their application and it also provides exclusive access to WaveNet voices from DeepMind. In this article, we are going to build a simple mobile App using the Cloud Text to Speech API where user can select the voices to use and the text to convert into speech. It uses Flutter so the app can run both on iOS and Android. You can access the project source code through the GitHub repository here.
What we will build
Here are the things that we will perform for this projet:
- Setup Google Cloud Text to Speech API
- Setup Flutter Project Dependencies
- Implement Google Cloud Text To Speech REST API with Dart
- Main Widget Implementation
Setup Google Cloud Text to Speech API
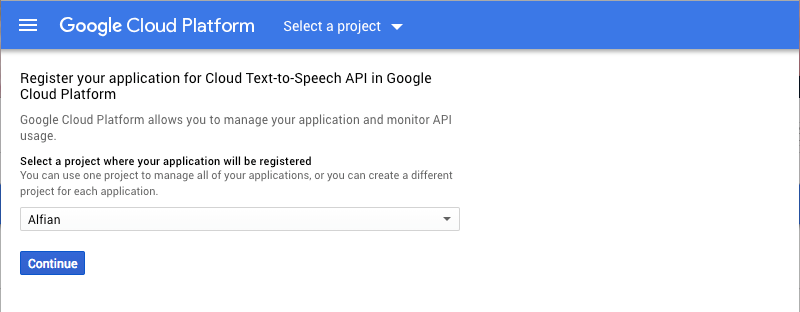
To start using the Google Cloud Text to Speech API you need to sign up into Google Cloud Platform. Follow the quickstart guide in here, make sure to enable the API for your project as shown in the screenshoot below.
After enabling the Cloud Text to Speech API, we need to create API Key to use in our project when making REST call. Go to API then Credentials from the sidebar and generate one API Key for the project as shown below the screenshot below.

Setup Flutter Project Dependency
Our Flutter project pubspec.yaml will be using 2 external dependencies:
- audioplayer: A Flutter audio plugin (ObjC/Java) to play remote or local audio files by Erick Ghaumez.
- path_provider: A Flutter plugin for finding commonly used locations on the filesystem. Supports iOS and Android by Flutter Team.
...
dependencies:
flutter:
sdk: flutter
cupertino_icons: ^0.1.2
audioplayer: ^0.5.0
path_provider: ^0.4.1
...
Implement Google Cloud Text To Speech REST API with Dart
Google Cloud Text To Speech does not provide native client libraries to use for Android and iOS. Instead we can use the provided REST API to interact with the Cloud Text To Speech API. There are 2 main endpoints we will use:
- /voices - Get list of all the voices available for the Cloud Text To Speech API for user to select.
- /text:synthesize -Perform text to speech synthesise by using the text, language, and audioConfig we provide.
TextToSpeechAPI class is the class we build to wrap the Cloud Text To Speech HTTP REST API with dart so we can provide public method for the client to perform the get voices and synthesise operation. Don’t forget to copy the API Key from the GCP console into the apiKey variable. All the HttpRequest will set the X-Goog-Api-Key HTTP header with the value of the apiKey.
The getVoices method is an async method that perform the GET HTTP request to the /voices endpoint. The response is a JSON containing the voices that we will map into list of simple Voice dart object. The Voice Class contains the name, languageCodes, and gender of the voice.
The synthesizeText method is an async method that receives text to synthesize, name and languageCode to use as the voice, and the audioConfig for the audio file. Based on the parameter we wrap it into a JSON object, for the audioEncoding we set the value to MP3. At last, we set the json object as a request body of the HttpRequest and perform the POST request to the /text:synthesize endpoint. The response will be a json object containing the audioOutput in Base64Encoded String.
import 'dart:io';
import 'dart:async';
import 'dart:convert' show json, utf8;
import 'package:flutter_wavenet/voice.dart';
class TextToSpeechAPI {
static final TextToSpeechAPI _singleton = TextToSpeechAPI._internal();
final _httpClient = HttpClient();
static const _apiKey = "YOUR_API_KEY";
static const _apiURL = "texttospeech.googleapis.com";
factory TextToSpeechAPI() {
return _singleton;
}
TextToSpeechAPI._internal();
Future<dynamic> synthesizeText(String text, String name, String languageCode) async {
try {
final uri = Uri.https(_apiURL, '/v1beta1/text:synthesize');
final Map json = {
'input': {
'text': text
},
'voice': {
'name': name,
'languageCode': languageCode
},
'audioConfig': {
'audioEncoding': 'MP3'
}
};
final jsonResponse = await _postJson(uri, json);
if (jsonResponse == null) return null;
final String audioContent = await jsonResponse['audioContent'];
return audioContent;
} on Exception catch(e) {
print("$e");
return null;
}
}
Future<List<Voice>> getVoices() async {
try {
final uri = Uri.https(_apiURL, '/v1beta1/voices');
final jsonResponse = await _getJson(uri);
if (jsonResponse == null) {
return null;
}
final List<dynamic> voicesJSON = jsonResponse['voices'].toList();
if (voicesJSON == null) {
return null;
}
final voices = Voice.mapJSONStringToList(voicesJSON);
return voices;
} on Exception catch(e) {
print("$e");
return null;
}
}
Future<Map<String, dynamic>> _postJson(Uri uri, Map jsonMap) async {
try {
final httpRequest = await _httpClient.postUrl(uri);
final jsonData = utf8.encode(json.encode(jsonMap));
final jsonResponse = await _processRequestIntoJsonResponse(httpRequest, jsonData);
return jsonResponse;
} on Exception catch(e) {
print("$e");
return null;
}
}
Future<Map<String, dynamic>> _getJson(Uri uri) async {
try {
final httpRequest = await _httpClient.getUrl(uri);
final jsonResponse = await _processRequestIntoJsonResponse(httpRequest, null);
return jsonResponse;
} on Exception catch(e) {
print("$e");
return null;
}
}
Future<Map<String, dynamic>> _processRequestIntoJsonResponse(HttpClientRequest httpRequest, List<int> data) async {
try {
httpRequest.headers.add('X-Goog-Api-Key', _apiKey);
httpRequest.headers.add(HttpHeaders.CONTENT_TYPE, 'application/json');
if (data != null) {
httpRequest.add(data);
}
final httpResponse = await httpRequest.close();
if (httpResponse.statusCode != HttpStatus.OK) {
throw Exception('Bad Response');
}
final responseBody = await httpResponse.transform(utf8.decoder).join();
return json.decode(responseBody);
} on Exception catch(e) {
print("$e");
return null;
}
}
}
class Voice {
final String name;
final String gender;
final List<String> languageCodes;
Voice(this.name, this.gender, this.languageCodes);
static List<Voice> mapJSONStringToList(List<dynamic> jsonList) {
return jsonList.map((v) {
return Voice(v['name'], v['ssmlGender'], List<String>.from(v['languageCodes']));
}).toList();
}
}
Main Widget Implementation
The app consists only of one main screen where user can select the voice to perform synthesize using DropdownButton and TextField where they can enter their text. The synthesize process will be performed when the user tap on the FloatingActionButton located at the bottom right corner.
There are 4 internal states:
- _voices: List containing the Voice object from the network.
- _selectedVoice: Selected voice for the Dropdown.
- _searchQuery: TextEditingController object to manage the state of the TextField.
- _audioPlugin: AudioPlayer object from the AudioPlayer package that will be used to play the audio file from the synthesize response.
As the Widget is created, the getVoices async method is invoked, inside it uses the TextToSpeechAPI getVoices method to get the list of voices from the network. After the response is received, setState is invoked and _voices is assigned with the response to trigger widget render.
The Widget itself uses a SingleChildScrollView as the root widget. Then it uses the Column Widget to stacks the children vertically on its main axis. The first children is the DropdownButton that uses the voices array and selectedVoice as its datasource builder and selected value. The TextField widget is configured so it can accept multiline text.
When the FloatingActionButton is pressed, the onPressed callback check if the TextField is not empty and the selected voice is not null, then the synthesizeText async method is invoked passing the TextField text. Inside the method, the TextToSpeech API synthesizeText method is invoked passing the text, selected voice name, and the languageCode.
After the synthesize response is returned, we check if the response is not null. Because the response from Google Cloud Text To Speech API is a Base64Encoded String, we will decode it into bytes using the Base64Decoder class passing the string. After that we will use the path_provider getTemporaryDirectory and create a temporary file for the audio so we can play it using the AudioPlayer plugin passing the temporary file path.
import 'package:flutter/material.dart';
import 'package:flutter_wavenet/TextToSpeechAPI.dart';
import 'dart:io';
import 'package:audioplayer/audioplayer.dart';
import 'dart:convert';
import 'package:path_provider/path_provider.dart';
import 'package:flutter_wavenet/voice.dart';
void main() => runApp(new MyApp());
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return new MaterialApp(
title: 'DeepMind WaveNet Text To Speech',
debugShowCheckedModeBanner: false,
theme: new ThemeData(
primarySwatch: Colors.teal,
),
home: new MyHomePage(title: 'DeepMind WaveNet Text To Speech'),
);
}
}
class MyHomePage extends StatefulWidget {
MyHomePage({Key key, this.title}) : super(key: key);
final String title;
@override
_MyHomePageState createState() => new _MyHomePageState();
}
class _MyHomePageState extends State<MyHomePage> {
List<Voice> _voices = [];
Voice _selectedVoice;
AudioPlayer audioPlugin = AudioPlayer();
final TextEditingController _searchQuery = TextEditingController();
initState() {
super.initState();
getVoices();
}
void synthesizeText(String text) async {
if (audioPlugin.state == AudioPlayerState.PLAYING) {
await audioPlugin.stop();
}
final String audioContent = await TextToSpeechAPI().synthesizeText(text, _selectedVoice.name, _selectedVoice.languageCodes.first);
if (audioContent == null) return;
final bytes = Base64Decoder().convert(audioContent, 0, audioContent.length);
final dir = await getTemporaryDirectory();
final file = File('${dir.path}/wavenet.mp3');
await file.writeAsBytes(bytes);
await audioPlugin.play(file.path, isLocal: true);
}
void getVoices() async {
final voices = await TextToSpeechAPI().getVoices();
if (voices == null) return;
setState(() {
_selectedVoice = voices.firstWhere((e) => e.name == 'en-US-Wavenet-F' && e.languageCodes.first == 'en-US', orElse: () => Voice('en-US-Wavenet-F', 'FEMALE', ['en-US']));
_voices = voices;
});
}
@override
Widget build(BuildContext context) {
return new Scaffold(
appBar: new AppBar(
title: new Text(widget.title),
),
body: SingleChildScrollView(child:
Column(children: <Widget>[
Padding(
padding: EdgeInsets.symmetric(vertical: 8.0, horizontal: 16.0),
child: DropdownButton<Voice>(
value: _selectedVoice,
hint: Text('Select Voice'),
items: _voices.map((f) => DropdownMenuItem(
value: f,
child: Text('${f.name} - ${f.languageCodes.first} - ${f.gender}'),
)).toList(),
onChanged: (voice) {
setState(() {
_selectedVoice = voice;
});
},
),
),
Padding(
padding: EdgeInsets.symmetric(vertical: 8.0, horizontal: 16.0),
child: TextField(
autofocus: true,
controller: _searchQuery,
keyboardType: TextInputType.multiline,
maxLines: null,
decoration: InputDecoration(
hintText: 'Please enter text to convert to WaveNet Speech'
),
),
)
])
),
floatingActionButton: FloatingActionButton(
elevation: 4.0,
child: Icon(Icons.audiotrack),
onPressed: () {
final text = _searchQuery.text;
if (text.length == 0 || _selectedVoice == null) return;
synthesizeText(text);
},
),
);
}
}
Conclusion
Google Cloud Text To Speech API powered by WaveNet DeepMind is a really amazing technology that can be used to synthesise and mimic real person voice. There are many real world project that can use this technology to empower user experience and interaction with computer such as call center automation, iOT embedded devices that responds to user, and media text transformation to audio. The new era of speech synthesise has only just begun with the era of AI and ML. Happy Fluttering!